Break Down Technical Barriers: Youdao Opens Full Source Code for "Ziyue 4" Dual-Core Engine, Hard-Rebuilding Chain-of-Thought to Cut Deployment Costs
Editorial standards and source policy: Editorial standards, Team. Content links to primary sources; see Methodology.
Youdao open-sources its upgraded "Ziyue 4" multimodal model and TTS engine—boosting visual and mathematical reasoning to state-of-the-art levels while cutting inference costs via chain-of-thought optimization.
Decision in 20 seconds
Youdao open-sources its upgraded "Ziyue 4" multimodal model and TTS engine—boosting visual and mathematical reasoning to state-of-the-art levels while cutting i…
Who this is for
Product managers and Developers who want a repeatable, low-noise way to track AI updates and turn them into decisions.
Key takeaways
- Ziyue 4 Enters the Multimodal Era
- Visual Math & Physics Reasoning Now Industry-Leading at Its Scale
- Rethinking Chain-of-Thought: Cutting Real Inference Cost
- TTS Released Open-Source: Supports 14 Languages, Voice Cloning in 3 Seconds
Recently, NetEase Youdao announced the official upgrade of its large language model series “Ziyue” to version 4.0. The product has evolved beyond isolated capabilities into a comprehensive, multimodal system. The new “Ziyue 4” supports seamless multimodal interaction—including text, images, and audio—and has open-sourced both its core multimodal model and text-to-speech (TTS) model. Meanwhile, its translation model has undergone deep technical refactoring—boosting both translation quality and inference efficiency.
From an industry perspective, this isn’t just another routine release. It signals something more consequential: domestic edtech and AI companies are now lowering the barrier to entry for developers—shifting the narrative from “capable of use” to “affordable, integrable, and deployable.”
Ziyue 4 Enters the Multimodal Era
The most immediate change with “Ziyue 4” is a broadened capability envelope. In the past, AI functions in education were often siloed—separate models for text Q&A, image understanding, and speech processing. Now, “Ziyue 4” unifies these capabilities under a single, cohesive multimodal architecture.
For product teams and developers, this delivers two tangible benefits:
- More natural, fluid interactions across input modalities (e.g., text + image + voice),
- Simpler integration—fewer API calls, less glue code, and reduced engineering overhead when building real-world applications.
Visual Math & Physics Reasoning Now Industry-Leading at Its Scale
One standout highlight of the open-sourced “Ziyue 4” multimodal model is its performance on visual math and physics tasks. Problems involving charts, equations, and complex layouts have long been among the hardest—and most practically relevant—in educational AI.
According to official benchmarks, the open-sourced multimodal model—trained at the 27B parameter scale—achieves top-tier visual reasoning performance among models of comparable size. On pure Chinese-language math and physics problems (text-only), accuracy has risen to 81.4%, further cementing its edge in education-specific use cases.
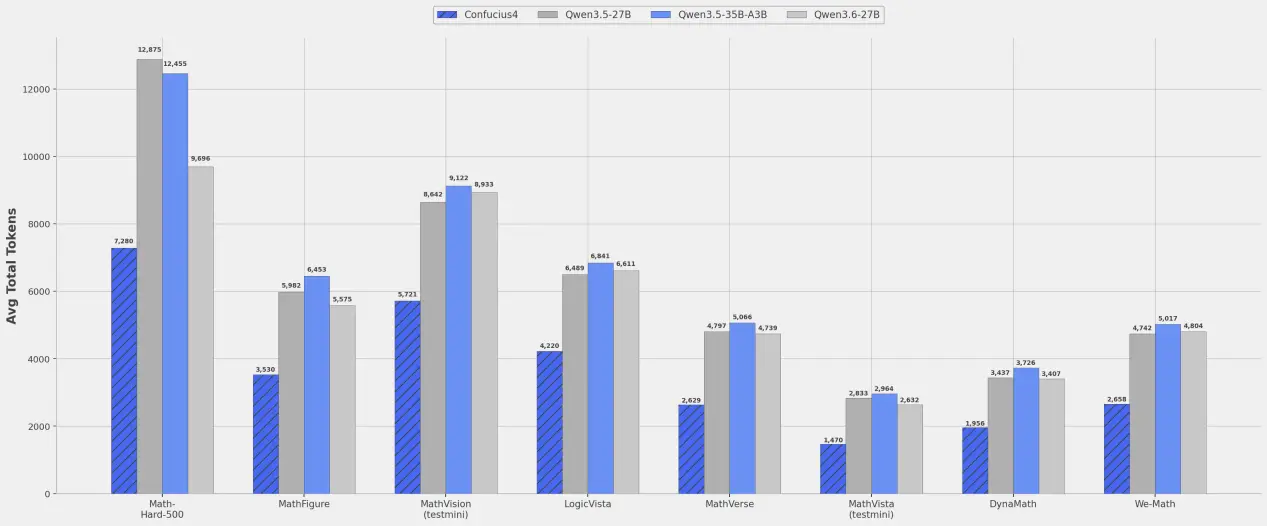
This capability isn’t just about “scoring well on leaderboards.” For education products, question banks, learning hardware, and photo-based problem-solving apps, visual math reasoning is one of the highest-value capabilities—because it mirrors real user needs most closely. The team that delivers greater stability here gains a real edge in embedding AI deeply into actual learning workflows—not just showcasing it in demos.
Rethinking Chain-of-Thought: Cutting Real Inference Cost
If capability ceiling determines whether a model can be used, then cost structure determines how widely it can be deployed. Beyond benchmark scores alone, what makes “Ziyue 4” especially noteworthy is its engineering-level optimization of the reasoning pipeline.
According to official documentation, the new model applies a refined chain-of-thought restructuring strategy. It leverages a large-scale dataset of high-quality, highly distilled reasoning examples for deep optimization—reducing average chain-of-thought output length by 43.2% during inference. In short: it’s not just about getting the right answer, but about getting it via a shorter, more efficient path.
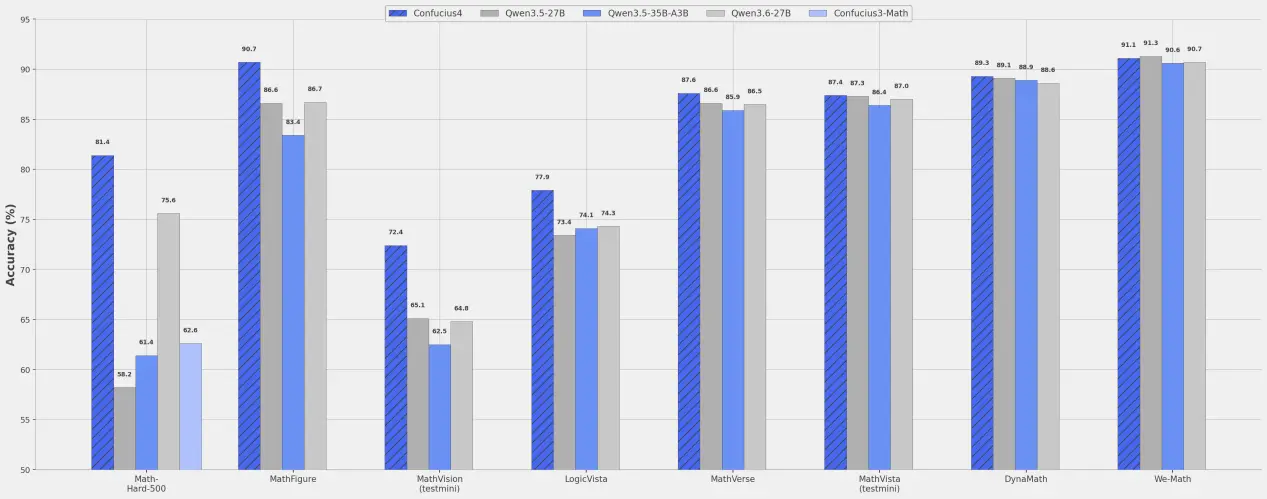
The impact is immediate and practical. For enterprises and developers calling large models, shorter reasoning chains mean fewer tokens consumed, faster response times, and lower inference costs. This is especially valuable in high-frequency, complex-reasoning, or long-chain interactive applications—where such optimizations often deliver more tangible ROI than isolated benchmark improvements.
TTS Released Open-Source: Supports 14 Languages, Voice Cloning in 3 Seconds
Alongside the multimodal model, Youdao has also open-sourced ZiYue-4’s text-to-speech (TTS) engine. Built on a “speech encoder + LLM” architecture, it’s designed specifically for developers and content creators—offering accessible voice cloning and expressive speech synthesis.
According to official documentation, the engine supports 14 languages: Chinese, English, Japanese, Korean, German, French, Spanish, Indonesian, Italian, Thai, Portuguese, Russian, Malay, and Vietnamese. It also enables cross-lingual voice consistency—preserving the same speaker’s timbre across different languages. With just any audio sample, users can clone a voice in as little as three seconds.
For use cases like content creation, language learning assistants, digital avatars, and multilingual dubbing, open-sourcing this capability lets product teams rapidly build production-ready voice experiences—without investing in building full TTS pipelines from scratch.
Translation Model Deeply Refactored: 80% Faster Inference
As one of Youdao’s most valuable technical assets, its translation model has also undergone a major upgrade. According to the official announcement, the team cleaned over 100 million multilingual training samples at the data level and introduced domain experts for multi-dimensional human evaluation. At the algorithmic level, they adopted an innovative “Multi-Expert OPD” architecture—enhanced with formatting rewards and language detection mechanisms—to tackle common machine-translation issues like off-target output and language mixing.
Even more significantly, under real-world high-frequency, high-concurrency business conditions, the new translation model achieves an 80% improvement in overall inference speed. This means it’s not just more accurate—it’s also production-ready for enterprise-grade systems requiring large-scale, multi-scenario deployments.
What This Upgrade Means for the Industry
Looking back, the upgrade—and full open-sourcing—of Ziyue 4 isn’t just about adding another model option. It signals a clearer industrial direction:
- Foundational AI capabilities must balance performance and cost-efficiency to truly integrate into real business workflows.
- Multimodal understanding, speech processing, and translation are no longer isolated modules—they’re converging into unified, product-ready capabilities.
- As models become increasingly optimized for complex, real-world educational tasks, they naturally generalize more easily to broader content, office productivity, and enterprise applications.
From this perspective, Ziyue 4 isn’t merely a parameter upgrade. It’s an effort to tightly connect foundational model capabilities, practical product scenarios, and the developer ecosystem into a cohesive, self-reinforcing loop. For teams building AI for education, content creation, or voice-driven interfaces, Ziyue 4 is a compelling open-source milestone worth watching closely.
Open-Source Repositories
Further Reading
- Weekly AI Release Tracking: A 25-Minute Retrospective Workflow Guide for 2026
- How to Decide in 2026 Whether an AI Update Is Worth Testing: A Decision Checklist for Product and Engineering Teams
- China AI Industry Developments 2026: What’s Actually Changing
- Tracking China’s Latest AI Developments: A Curated Guide to the Best English-Language Sources (2026)
RadarAI aggregates high-quality AI updates and open-source intelligence to help developers efficiently track industry trends—and quickly assess which innovations are ready for real-world implementation.
FAQ
How much time does this take? 20–25 minutes per week is enough if you use one signal source and keep a strict timebox.
What if I miss something important? If it truly matters, it will resurface across multiple sources. A consistent weekly routine beats daily scanning without decisions.
What should I do after I shortlist items? Pick one concrete follow-up: prototype, benchmark, add to a watchlist, or validate with users—then write down the source link.
Related reading
- Build an AI Monitoring Stack That Actually Helps a Team Decide
- Top China-Built AI Models to Watch in 2026: DeepSeek, Qwen, Kimi & More
- China AI Updates in English: What Builders Should Watch Each Month
- How to Track China AI in English Without Doomscrolling
RadarAI helps builders track AI updates, compare source-backed signals, and decide which changes are worth acting on.