打破技术壁垒!有道“子曰4”双核心引擎全量开源,思维链硬核重构直击落地成本
编辑标准与来源政策: 编辑标准, 团队. 内容均链至原始来源,见 方法论.
近日,网易有道宣布“子曰”大模型正式升级到 4.0 版本,产品形态也从单点能力迭代走向更完整的全模态体系。新版“子曰4”不仅支持文本、图片、音频等多模态融合交互,还把核心的多模态模型与语音合成(TTS)模型一起开源。与此同时,翻译模型也完成了一轮深度技术重构,翻译质量与推理效率同步提升。
从行业视角看,这次升级并不只是一次常规发版。它释放出一个更关键的信号:国内教育与 AI 厂商开始把底层能力以更低门槛的方式开放给开发者,让“能用”逐渐变成“用得起、接得上、跑得动”。
子曰4进入全模态时代
这次“子曰4”的升级,最直接的变化是能力边界被整体拉宽了。过去很多教育场景中的 AI 能力往往是分散的,例如文本问答一套模型、图像理解一套模型、语音能力再单独接一套引擎。现在,“子曰4”在架构层面开始把这些能力合并到一个更统一的全模态框架中。
对于产品团队和开发者而言,这意味着两个现实价值:一是多种输入形式之间的联动更自然,二是后续做实际业务集成时,调用链路和能力拼装的复杂度会更低。
视觉数理能力拉到同规模领先水平
在官方信息中,“子曰4”多模态模型最突出的亮点之一,是它在视觉数理任务上的表现。针对带图表、带公式、带复杂版面的数学与物理题,这类问题一直是教育场景里最难、也最接近真实使用需求的部分。
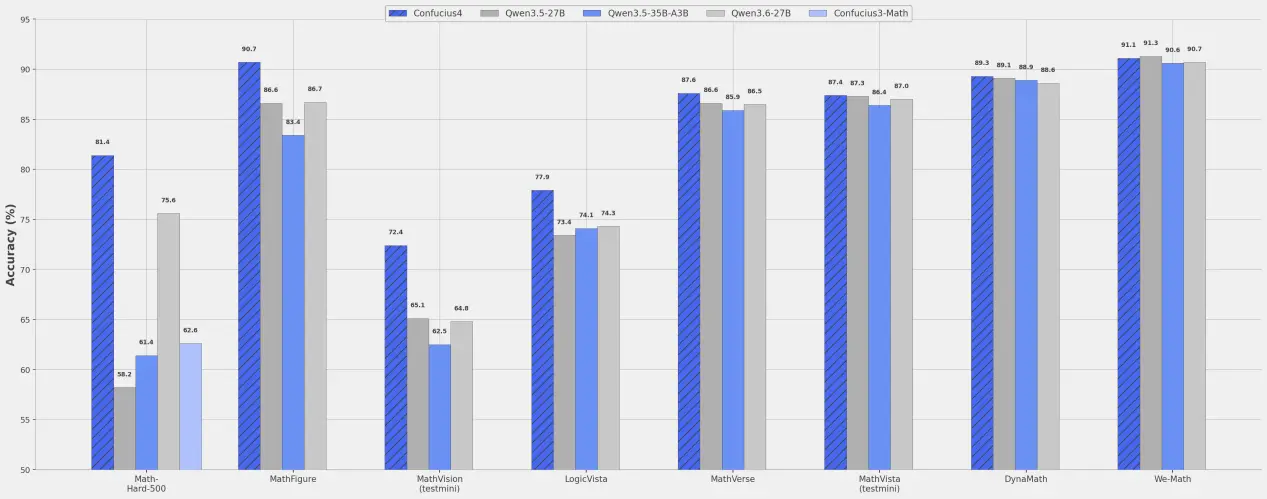
据介绍,开源的“子曰4”多模态模型在 27B 参数规模上,把视觉输入下的数理能力提升到了同规模模型中的最佳水平。除了视觉题,中文纯文本数理难题上的准确率也提升到 81.4%,继续强化了它在教育场景下的针对性。
这类能力并不只是“刷榜好看”。对教育产品、题库工具、学习硬件、拍题应用来说,视觉数理是最贴近真实真实问题的一类高价值能力。谁能在这部分做得更稳定,谁就更有机会把 AI 真正嵌进学习流程,而不是只停留在演示层。
思维链重构,把推理成本真正打下来
如果说能力上限决定了模型能不能用,那么成本结构决定了模型能不能大规模落地。相比单纯强调基准成绩,这次“子曰4”更值得关注的一点,是它对推理链路做了更细的工程优化。
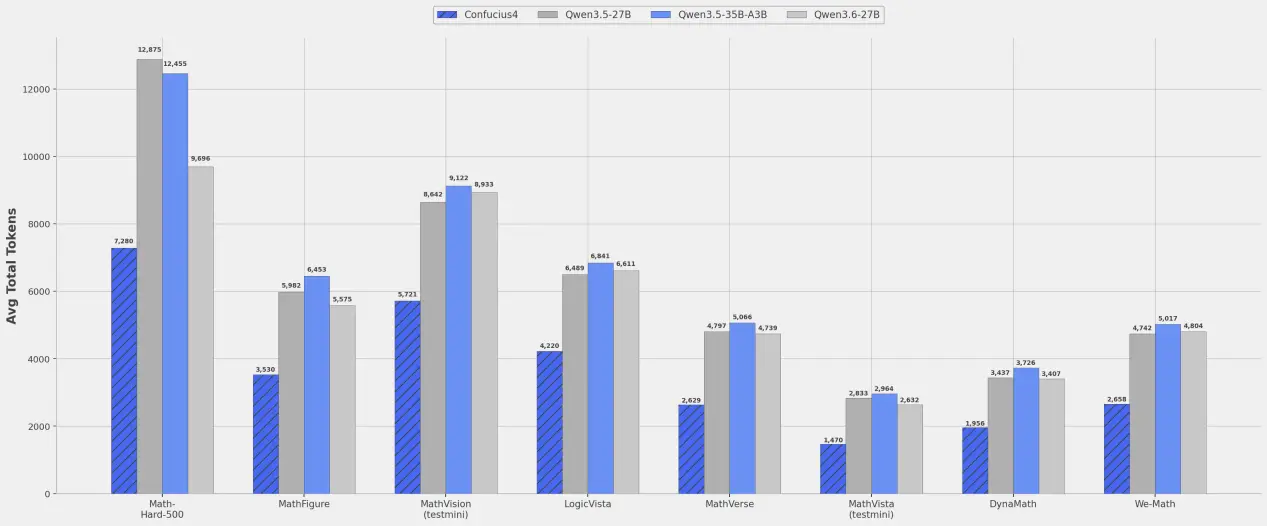
根据官方介绍,新模型通过精细化思维链重构方案,汇聚大规模优质且更精简的推理样本进行深度优化,最终把推理时的思维链输出长度压缩了 43.2%。换句话说,它不是只追求“能答对”,而是追求“用更短的路径答对”。
这件事的意义非常直接。对于调用大模型的企业和开发者来说,更短的思维链意味着更少的 token 消耗、更快的响应速度,以及更低的推理成本。尤其在需要高频调用、复杂推理、长链路交互的业务中,这种优化往往比单点 benchmark 提升更能影响真实 ROI。
TTS 同步开源:14 种语言、3 秒克隆原声
这次和多模态模型一起开源的,还有“子曰4”的语音合成(TTS)引擎。该引擎基于“语音编码器 + LLM”的架构,重点面向开发者和内容创作者提供低门槛的语音克隆与情感合成能力。
从官方披露的能力看,它已经支持中文、英语、日语、韩语、德语、法语、西班牙语、印尼语、意大利语、泰语、葡萄牙语、俄语、马来语和越南语共 14 种语言,并支持不同语言间保持同一说话者音色的一致迁移。用户只需提供任意音频素材,系统即可在 3 秒内完成原声复制。
对内容生产、教育陪练、数字人、跨语种配音等场景来说,这类能力一旦开源,就意味着更多产品团队可以在更低预算下快速做出可交付的语音体验,而不必从头搭建整套语音合成链路。
翻译模型深度重构,推理速度提升 80%
作为有道最深的技术资产之一,翻译模型这次也完成了重要升级。官方表示,团队在数据层面清洗了上亿级多语言语料,并引入专业人员进行多维度人工评估;在算法层面,则采用了创新的“多专家 OPD”模式,并加入格式奖励和语言检测机制,解决机翻中常见的脱靶与语种混出问题。
更重要的是,在高频、高并发的真实业务环境下,新一代翻译模型的整体推理速度提升达到 80%。这意味着它不只是质量更强,也更适合进入企业级、多场景、大规模调用的产品系统里。
这次升级对行业意味着什么
回过头看,“子曰4”的升级和全量开源,价值并不只在于又多了一个可选模型,而在于它展示了一种更明确的产业方向:
- 底层能力要同时兼顾效果与成本,才能真正走进业务;
- 多模态、语音、翻译不再是彼此割裂的能力模块,而是会逐步汇成统一产品能力;
- 当教育场景里的复杂真实任务被持续优化后,这类模型也更容易迁移到更广泛的内容、办公与企业场景。
从这个角度说,“子曰4”不是单纯做了一次参数升级,而是在试图把底层模型能力、产品场景和开发者生态连接成一个更完整的闭环。对于想做教育 AI、内容 AI、语音交互产品的团队来说,这会是一个值得持续观察的开源节点。
开源地址
延伸阅读
- 每周追踪 AI 发布:2026 年 25 分钟复盘流程搭建指南
- 2026 年怎么判断一条 AI 更新值不值得测试:一个给产品和开发团队的决策清单
- China AI Industry Developments 2026: What's Actually Changing
- 追踪中国 AI 最新动态:最好用的英文信息源指南(2026)
RadarAI 聚合 AI 优质更新与开源信息,帮助开发者高效追踪 AI 行业动态,快速判断哪些方向具备了落地条件。